

Tracking a Job Change with UTMs and Resume Hyperlinks
A totally unesscesary use of simple Python and UTM basics

Thought
I got curious if recruiters or hiring managers were even reading my resume, let alone clicking on the links I provided them on my resume. So I got curious.. how can I get concrete visibility into their engagement?
Here is what the top of my resume looks like

I came up with the thought that I could append UTMs to each of these links for different respective companies. I also figured I could do it programmatically instead of creating a new PDF for each company and manually editing the hyperlinks.
First Step -- Create a Company Tracking List
I started a CSV file that looks like this:
| Company | campaign | source | medium |
| Blizzard | job_search_mar22 | resume_ref_v1 | blizzard |
| Anduril | job_search_mar22 | resume_ref_v1 | anduril |
| Boston Dynamics | job_search_mar22 | resume_ref_v1 | boston_d |
It's not too much work to maintain this list, I updated it every time I was getting ready to apply for a job.
Next Step -- Create a Python Script
Loop over CSV records from the CSV tracker list
Read my current resume and extract all hyperlinks using the
pdfrwlibraryLoop over all companies and modify all hyperlinks
Save a new PDF for each company
import pdfrw
import csv
def get_csv_records(company_file):
with open(company_file, 'r') as csv_file:
csv_reader = csv.DictReader(csv_file)
return [row for row in csv_reader]
def create_pdf(row,resume_base_file):
# Load the PDF file
base_pdf = pdfrw.PdfReader(resume_base_file)
page = base_pdf.pages[0]
# Create an empty PDF file
new_pdf = pdfrw.PdfWriter()
# Check if the page has any hyperlinks
for annot in page.Annots or []:
old_url = annot.A.URI
if old_url == None:
continue
# Replace the old path with the new path
old_url = str(old_url).strip().replace('(','').replace(')','')
new_url = (
f'({old_url}\n'
f'?utm_campaign={row["campaign"]}\n'
f'&utm_source={row["source"]}\n'
f'&utm_medium={row["medium"]})\n'
)
# Convert the new string for PDF strings
new_url = pdfrw.objects.pdfstring.PdfString(new_url)
# Update the hyperlink
annot.A.URI = new_url
# Add the modified page to the new PDF file
new_pdf.addpage(page)
# Save the modified PDF file
new_pdf.write(f'Resume_MyName_{row["Company"].strip()}.pdf')
def main():
resume_base_file = 'resume_base.pdf'
company_file = 'company_list.csv'
data = get_csv_records(company_file)
for row in data:
create_pdf(row,resume_base_file)
if __name__ == "__main__":
main()
I won't break down the code too much, it's fairly straightforward consisting of two core functions, reading in the CSV file and creating a new PDF for each record (Company) in the CSV.
Within the create_pdf() function I utilized the pdfrw library to read the base resume file, and create a new page object based on the base resume. Then we can extract all strings from the page using page.Annots , then we can see if any of those strings meet the criteria of a URI (a web address on the resume).
If the string is a URI, I do some light cleanup on the link and then append/construct the UTMs from the CSV record.
Lastly, the PDF is saved as a new PDF. Essentially we're modifying the base resume each time and then saving it under a different name.
Before Executing
After Executing
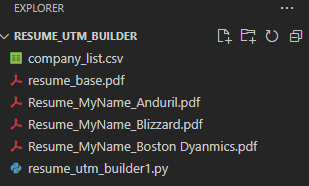
I can now shoot off customized resumes to all respective companies. The resume companies will receive will have specific UTMs appended to all hyperlinks in my resume, I'll now be able to see if anyone from Blizzard looked at my resume vs. Anduril.
Conclusion
The totally overengineered result is a neat little Google Analytics 4 chart that I can track the analytics on for any user who clicks the link(s).
I'm able to drill into the detail of whom is looking at my resume, for how long, how often and if they navigate elsewhere within my site(s)
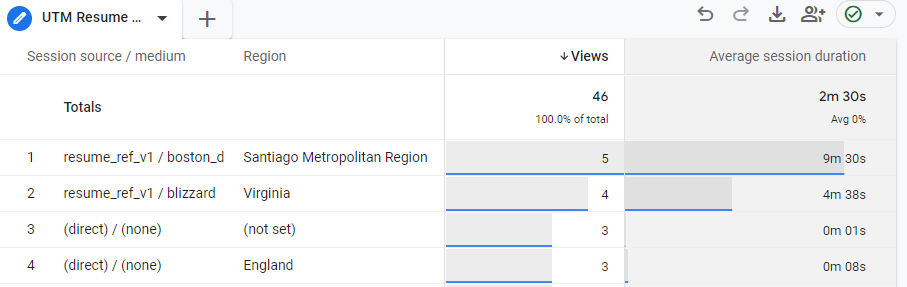
If you'd like to set this up on your own, just remember you need a GA4 property on a website that you own and of course, you need access to that property. In my case, I am also appending UTMs to my Github profile but I'll never be able to see those metrics because I don't own that site of course. In contrast, I have full analytics visibility into my Portfolio site and this Hashnode Blog.
Thanks for reading! Feel free to ask questions if you'd like to know more!



